- Fermi Whitepaper
- Kepler Whitepaper
- Maxwell Whitepaper
- Fast Tessellated Rendering on Fermi GF100
- Programming Guidelines and GPU Architecture Reasons Behind Them

GPUs are super parallel work distributors
Why all this complexity? In graphics we have to deal with data amplification that creates lots of variable workloads. Each drawcall may generate a different amount of triangles. The amount of vertices after clipping is different from what our triangles were originally made of. After back-face and depth culling, not all triangles may need pixels on the screen. The screen size of a triangle can mean it requires millions of pixels or none at all.
As a consequence modern GPUs let their primitives (triangles, lines, points) follow a logical pipeline, not a physical pipeline. In the old days before G80's unified architecture (think DX9 hardware, ps3), the pipeline was represented on the chip with the different stages and work would run through it one after another. G80 essentially reused some units for both vertex and fragment shader computations, depending on the load, but it still had a serial process for the primitives/rasterization and so on. With Fermi the pipeline became fully parallel, which means the chip implements a logical pipeline (the steps a triangle goes through) by reusing multiple engines on the chip.
Let's say we have two triangles A and B. Parts of their work could be in different logical pipeline steps. A has already been transformed and needs to be rasterized. Some of its pixels could be running pixel-shader instructions already, while others are being rejected by depth-buffer (Z-cull), others could be already being written to framebuffer, and some may actually wait. And next to all that, we could be fetching the vertices of triangle B. So while each triangle has to go through the logical steps, lots of them could be actively processed at different steps of their lifetime. The job (get drawcall's triangles on screen) is split into many smaller tasks and even subtasks that can run in parallel. Each task is scheduled to the resources that are available, which is not limited to tasks of a certain type (vertex-shading parallel to pixel-shading).
Think of a river that fans out. Parallel pipeline streams, that are independent of each other, everyone on their own time line, some may branch more than others. If we would color-code the units of a GPU based on the triangle, or drawcall it's currently working on, it would be multi-color blinkenlights :)
GPU architecture

The work that a programmer thinks of (shader program execution) is done on the SMs. It contains many Cores which do the math operations for the threads. One thread could be a vertex-, or pixel-shader invocation for example. Those cores and other units are driven by Warp Schedulers, which manage groups of 32 threads as warps and hand over the instructions to be performed to Dispatch Units. The code logic is handled by the scheduler and not inside a core itself, which just sees something like "sum register 4234 with register 4235 and store in 4230" from the dispatcher. A core itself is rather dumb, compared to a CPU where a core is pretty smart. The GPU puts the smartness into higher levels, it conducts the work of an entire ensemble (or multiple if you will).
How many of these units are actually on the GPU (how many SMs per GPC, how many GPCs..) depends on the chip configuration itself. As you can see above GM204 has 4 GPCs with each 4 SMs, but Tegra X1 for example has 1 GPC and 2 SMs, both with Maxwell design. The SM design itself (number of cores, instruction units, schedulers...) has also changed over time from generation to generation (see first image) and helped making the chips so efficient they can be scaled from high-end desktop to notebook to mobile.
The logical pipeline
For the sake of simplicity several details are omitted. We assume the drawcall references some index- and vertexbuffer that is already filled with data and lives in the DRAM of the GPU and uses only vertex- and pixelshader (GL: fragmentshader).
- The program makes a drawcall in the graphics api (DX or GL). This reaches the driver at some point which does a bit of validation to check if things are "legal" and inserts the command in a GPU-readable encoding inside a pushbuffer. A lot of bottlenecks can happen here on the CPU side of things, which is why it is important programmers use apis well, and techniques that leverage the power of today's GPUs.
- After a while or explicit "flush" calls, the driver has buffered up enough work in a pushbuffer and sends it to be processed by the GPU (with some involvement of the OS). The Host Interface of the GPU picks up the commands which are processed via the Front End.
- We start our work distribution in the Primitive Distributor by processing the indices in the indexbuffer and generating triangle work batches that we send out to multiple GPCs.
- Within a GPC, the Poly Morph Engine of one of the SMs takes care of fetching the vertex data from the triangle indices (Vertex Fetch).
- After the data has been fetched, warps of 32 threads are scheduled inside the SM and will be working on the vertices.
- The SM's warp scheduler issues the instructions for the entire warp in-order. The threads run each instruction in lock-step and can be masked out individually if they should not actively execute it. There can be multiple reasons for requiring such masking. For example when the current instruction is part of the "if (true)" branch and the thread specific data evaluated "false", or when a loop's termination criteria was reached in one thread but not another. Therefore having lots of branch divergence in a shader can increase the time spent for all threads in the warp significantly. Threads cannot advance individually, only as a warp! Warps, however, are independent of each other.
- The warp's instruction may be completed at once or may take several dispatch turns. For example the SM typically has less units for load/store than doing basic math operations.
- As some instructions take longer to complete than others, especially memory loads, the warp scheduler may simply switch to another warp that is not waiting for memory. This is the key concept how GPUs overcome latency of memory reads, they simply switch out groups of active threads. To make this switching very fast, all threads managed by the scheduler have their own registers in the register-file. The more registers a shader program needs, the less threads/warps have space. The less warps we can switch between, the less useful work we can do while waiting for instructions to complete (foremost memory fetches).
- Once the warp has completed all instructions of the vertex-shader, its results are being processed by Viewport Transform. The triangle gets clipped by the clipspace volume and is ready for rasterization. We use L1 and L2 Caches for all this cross-task communication data.
- Now it gets exciting, our triangle is about to be chopped up and potentially leaving the GPC it currently lives on. The bounding box of the triangle is used to decide which raster engines need to work on it, as each engine covers multiple tiles of the screen. It gets sent out to one or multiple GPCs via the Work Distribution Crossbar. We effectively split our triangle into lots of smaller jobs now.
- Attribute Setup at the target SM will ensure that the interpolants (for example the outputs we generated in a vertex-shader) are in a pixel shader friendly format.
- The Raster Engine of a GPC works on the triangle it received and generates the pixel information for those sections that it is responsible for (also handles back-face culling and Z-cull).
- Again we batch up 32 pixel threads, or better say 8 times 2x2 pixel quads, which is the smallest unit we will always work with in pixel shaders. This 2x2 quad allows us to calculate derivatives for things like texture mip map filtering (big change in texture coordinates within quad causes higher mip). Those threads within the 2x2 quad whose sample locations are not actually covering the triangle, are masked out (gl_HelperInvocation). One of the local SM's warp scheduler will manage the pixel-shading task.
- The same warp scheduler instruction game, that we had in the vertex-shader logical stage, is now performed on the pixel-shader threads. The lock-step processing is particularly handy because we can access the values within a pixel quad almost for free, as all threads are guaranteed to have their data computed up to the same instruction point (NV_shader_thread_group).
- Are we there yet? Almost, our pixel-shader has completed the calculation of the colors to be written to the rendertargets and we also have a depth value. At this point we have to take the original api ordering of triangles into account before we hand that data over to one of the ROP (render output unit) subsystems, which in itself has multiple ROP units. Here depth-testing, blending with the framebuffer and so on is performed. These operations need to happen atomically (one color/depth set at a time) to ensure we don't have one triangle's color and another triangle's depth value when both cover the same pixel.
NVIDIA typically applies memory compression, to reduce memory bandwidth requirements, which increases "effective" bandwidth (see GTX 980 pdf).






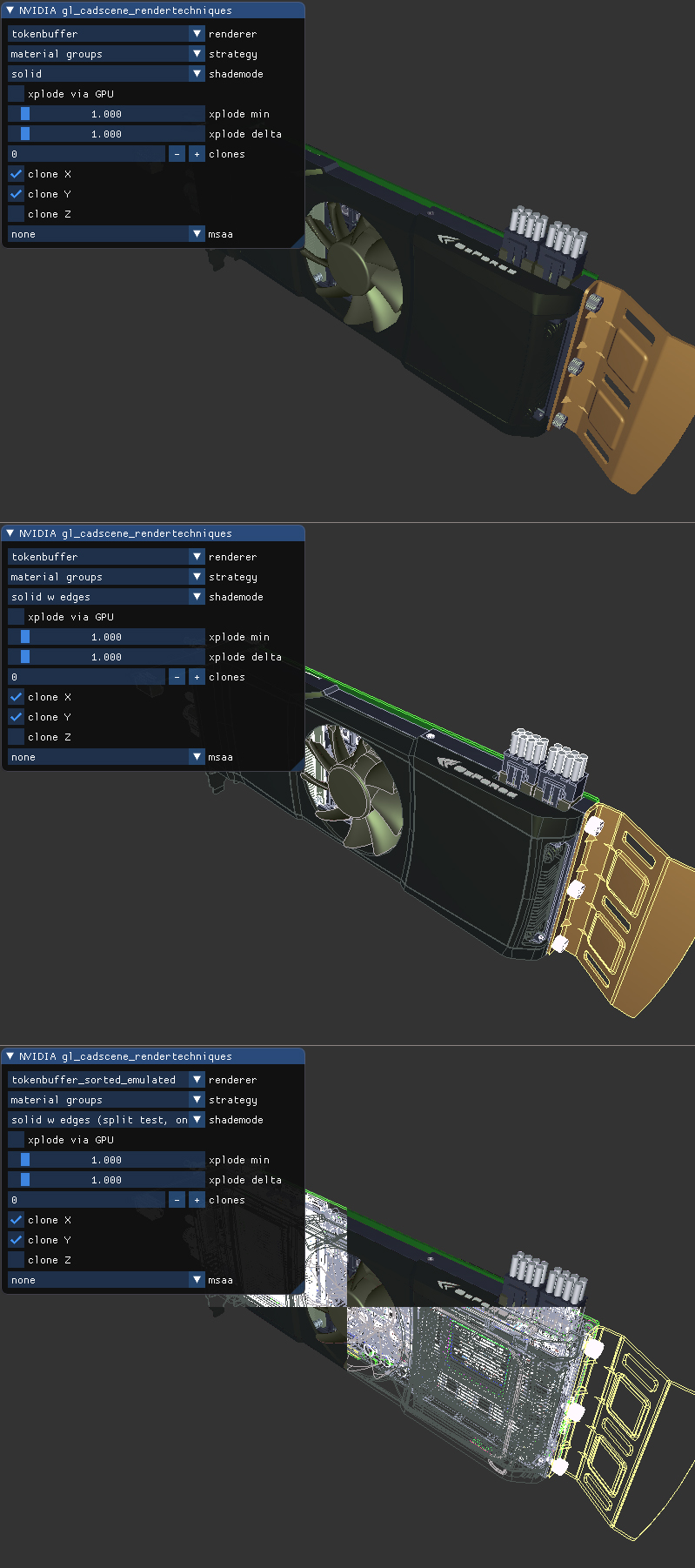
In the image below you can see how we rendered a CAD model and colored it by the different SMs or warp ids that contributed to the image (NV_shader_thread_group). The result would not be frame-coherent, as the work distribution will vary frame to frame. The scene was rendered using many drawcalls, of which several may also be processed in parallel (using NSIGHT you can see some of that drawcall parallelism as well).

Further reading
Next to the white papers mentioned at the beginning, the article series "A trip through the graphics-pipeline" by Fabian Giesen is worth a read and there is also a quite in-depth talk on the details of the memory and instruction processing on the SM by Paulius Micikevicius. Pomegranate: A Fully Scalable Graphics Architecture describes the concept of parallel stages and work distribution between them.This post here was motivated to help clear up some "serial issues" of version 1.1 of the very nicely-illustrated Render Hell by Simon Trümpler, looking forward to a new revision of that :)